
From the ICID Handbook to JSON: Accessing Cosmetic Ingredient Data Programmatically
Why Cosmetic Ingredient Data Is Fragmented Across Regulators — And What That Costs You
You're three sprints into a skincare scanner app. The PM wants users to point their phone at a product label and see ingredient safety in under a second. You assumed there'd be one canonical source — maybe the International Cosmetic Ingredient Dictionary and Handbook (ICID), the Personal Care Products Council's reference standard — and you'd just pull JSON. Instead you find a printed two-volume reference, the EU CosIng database behind a CSV export, the FDA's Voluntary Cosmetic Registration Program data buried in PDF appendices, and Health Canada's Cosmetic Ingredient Hotlist as an HTML table. None of them agree on synonym spelling. None return scores. None hit your 100ms latency budget.This article walks through how cosmetic ingredient data flows from regulatory references like the international cosmetic ingredient dictionary handbook into structured, queryable JSON — and what fields, endpoints, and trade-offs matter when you wire it into production. The goal is practical: by the end you should know which source belongs where in your stack, what a defensible API response looks like, and how to ship a feature without inheriting compliance debt.

Table of Contents
- Why Cosmetic Ingredient Data Is Fragmented Across Regulators — And What That Costs You
- From Reference Handbook to Live Endpoint: Comparing Four Ways to Source Ingredient Data
- Inside the JSON: The Ten Fields Every Cosmetic Ingredient API Should Return
- Single Lookup vs. Batch Analyze: Matching Endpoint Patterns to Product Behavior
- A Working Example: Authenticating, Querying, and Handling Errors End to End
- Official SDKs, Raw HTTP, or Generated Clients: Picking Your Integration Layer
- Pre-Launch Audit: The Compliance, Monitoring, and Cost Control Checklist
Why Cosmetic Ingredient Data Is Fragmented Across Regulators — And What That Costs You
A developer integrating cosmetic ingredient data hits four primary authoritative sources, each shipping in a different format.
First, the International Cosmetic Ingredient Dictionary and Handbook — published by the Personal Care Products Council. It's the global authority for assigning INCI names (International Nomenclature of Cosmetic Ingredients). It exists as a multi-volume printed reference and a licensed digital subscription (wINCI). It is not a public API. When you see "Aqua" instead of "Water" on a label, that convention traces back to ICID. This is the source of truth for nomenclature standardization, full stop.
Second, EU CosIng — the European Commission's Cosmetic Ingredients database. Public, web-based, downloadable as CSV. Contains regulatory annex references: Annex II banned substances, Annex III restricted, Annex IV colorants, Annex V preservatives, Annex VI UV filters. The schema is EU-specific and the export does not normalize to other jurisdictions.
Third, FDA cosmetic ingredient resources. Spread across the Voluntary Cosmetic Registration Program (VCRP, sunset in 2023 and replaced under the Modernization of Cosmetics Regulation Act of 2022 — MoCRA), the prohibited and restricted substances list in 21 CFR 700.11–700.35, and color additive lists. Mostly published as web pages and PDFs.
Fourth, the Health Canada Cosmetic Ingredient Hotlist — a two-tier list (prohibited, restricted) published as HTML.
Now stack the integration costs of going direct to those four sources:
- Schema normalization tax. The same ingredient — phenoxyethanol, say — appears with different identifier formats (CAS 122-99-6, EC 204-589-7), different synonym sets per source, and different "restricted" flag semantics. You write a mapping layer for every source you touch.
- Update cadence mismatch. The ICID Handbook updates annually. CosIng updates when EU regulation amends (irregular). FDA updates as rules or warning letters issue. Health Canada updates the Hotlist roughly every 2–3 years. Your sync job can't assume any fixed cadence — it has to poll, diff, and reconcile.
- No severity scoring. None of the primary regulators publish a 0–5 comedogenicity or irritancy score. Those scores exist in dermatology literature — Fulton's comedogenicity scale, originally published in the Journal of the Society of Cosmetic Chemists in 1984 — but you have to assemble them yourself and defend the methodology.
- Legal risk of scraping. ICID Handbook content is copyrighted by PCPC. Scraping incibeauty.com, incidecoder.com, or paula's choice violates ToS. Web scraping as a data strategy is fragile and exposes you to takedown notices and breach-of-contract claims that can derail a product launch.
Even after assembling all of this, you still need sub-100ms latency at query time. Bulk downloads and nightly ETL get you to a queryable index — but the engineering required to maintain that index is what most teams underestimate. Plan for an initial integration of 4–8 engineering weeks and quarterly maintenance cycles thereafter to track regulatory amendments and re-baseline synonym coverage.
The decision isn't "build vs. buy the data." It's something more uncomfortable: build vs. buy the normalization and maintenance pipeline that wraps the data.
The choice isn't whether to build or buy the data. It's whether to build or buy the normalization and maintenance pipeline around it.
From Reference Handbook to Live Endpoint: Comparing Four Ways to Source Ingredient Data
Four realistic options exist for getting cosmetic ingredient data into a production application: licensing the international cosmetic ingredient dictionary handbook digitally, calling regulator sources directly, using an aggregator platform, or consuming a normalized REST API. Each option carries a distinct cost profile, freshness story, and latency envelope. Pick wrong and you spend the first quarter rebuilding the integration.
| Aspect | ICID Handbook (Print / wINCI) | Direct Regulator Sources | Aggregator Platforms | Normalized REST API |
|---|---|---|---|---|
| Primary format | Print + licensed digital | CSV, HTML, PDF | Proprietary JSON/web | OpenAPI 3 / JSON |
| Update cadence | Annual editions | Irregular | Variable (weeks) | Continuous sync |
| Ingredient coverage | ~22,000+ INCI entries | Regional, with gaps | 15,000–25,000 | 25,000+ across regions |
| Severity scoring | None (descriptive) | Regulatory flags only | Sometimes proprietary | Standardized 0–5 |
| Identifier mapping | Partial | Region-specific | Partial | Full cross-mapping |
| Query latency | N/A (manual) | 200–2,000ms | 150–500ms | <100ms median |
| Cost model | License fee per seat | Free + engineering | Subscription | Credit-based |

The ICID Handbook is irreplaceable as the nomenclature authority — INCI names themselves originate there, and any production app must use INCI names exactly as the PCPC assigns them. But the Handbook is a reference, not an endpoint. You can license wINCI for internal lookup, but it doesn't return JSON, it doesn't sync to your backend, and it doesn't carry the severity scoring or jurisdictional safety_status your product needs at runtime.
Direct regulator sources are free, which is misleading. The engineering cost — writing parsers for HTML tables, monitoring for schema changes, reconciling synonyms across CosIng and the FDA's CFR — typically runs 4–8 engineering weeks for the initial integration with ongoing maintenance every quarter. For a two-engineer startup, that's a meaningful tax against feature velocity.
Aggregator platforms close the coverage gap but often hide methodology. If a platform returns "irritancy: high" without citing whether that's derived from Cosmetic Ingredient Review panels, EU SCCS opinions, or peer-reviewed literature, your compliance team can't defend the score in an audit. That opacity becomes a problem the first time a regulator or retail partner asks for citations.
A normalized REST API designed for programmatic consumption — returning standardized 0–5 scores, full synonym arrays, cross-jurisdiction safety_status, and CAS/EC identifiers in a single response — collapses the integration to a single client. The trade-off is dependency on a vendor's freshness commitment and SLA. For most production teams shipping to multiple markets, that trade-off pays for itself within the first quarter through saved engineering cycles alone.
Inside the JSON: The Ten Fields Every Cosmetic Ingredient API Should Return
When you decode the JSON from any ingredient lookup, you're looking at roughly ten core fields. Knowing what each is for — and what it isn't — separates a defensible product feature from a liability sitting in your UI. The table below names each field and the trap that comes with it.
| Field | Purpose | Example | What it does NOT mean |
|---|---|---|---|
inci_name | Canonical INCI name | "Sodium Lauryl Sulfate" | Not the marketing label name |
synonyms | Aliases, trade names | ["SLS", "Sodium Dodecyl Sulfate"] | Not exhaustive |
cas | CAS Registry number | "151-21-3" | Not a safety indicator |
ec / einecs | EU inventory ID | "205-788-1" | EU linkage only |
comedogenicity_score | 0–5 scale (Fulton-derived) | 3 | Not concentration-adjusted |
irritancy_score | 0–5 scale | 4 | Not skin-type specific |
allergen_flags | EU Annex III declarables | ["fragrance", "limonene"] | Not a medical diagnosis |
safety_status | Per-jurisdiction status | "approved_eu_restricted_us" | Not universal safe/unsafe |
category | Functional class | "Surfactant (Anionic)" | Not formulation function |
regulatory_notes | Concentration limits | "EU: max 2% leave-on" | Not legal advice |
Three of these fields deserve specific engineering attention.
Severity scores are scalar, not categorical. A comedogenicity_score of 3 is meaningful relative to 1 or 5, but it isn't a clinical diagnosis. The 0–5 scale traces back to Fulton's rabbit-ear assay methodology (1984), which has known limitations — it overestimates risk for some ingredients compared to human in-use testing. Surface the score and let users see methodology. Don't gate the UI on "score > 3 = bad"; render the number and let users interpret. Anything else trains users to treat your app as a verdict engine, which is exactly the liability posture you want to avoid.
safety_status is jurisdictional, not universal. A mature API returns something like "approved_eu_restricted_us" rather than a true/false boolean. Your client code must know which region the user is in before rendering a verdict. The 24 declarable fragrance allergens listed in EU Annex III of Regulation 1223/2009 — limonene, linalool, citronellol, and others — are not flagged the same way under FDA rules. Same molecule, different disclosure regime.
Synonym arrays are how you avoid building a fuzzy matcher. If a user types "SLS" or scans a label that reads "sodium dodecyl sulfate," both should resolve to the same inci_name. Calling the API with the raw user input and trusting the synonym index — backed by the CAS Registry for chemical identity — is faster and more correct than writing Levenshtein distance logic on the client. That index is doing work you'd otherwise spend a sprint replicating poorly.
The fields you don't see in a good response are equally telling: no "overall safety grade," no "natural/synthetic" boolean, no marketing categories like "clean." Those are interpretive layers your product builds — not data points an API should pretend to ship.
Single Lookup vs. Batch Analyze: Matching Endpoint Patterns to Product Behavior
Most cosmetic ingredient APIs expose two endpoint patterns — a single-ingredient GET and a batch POST. Picking the right one isn't about which is "better." It's about which matches the latency, cost, and UX shape of the feature you're shipping.
- Single-Ingredient Lookup —
GET /v1/ingredients/{name}- Request shape: URL-encoded ingredient name, synonym, or CAS number as the path parameter. Auth via bearer token in the header.
- Response shape: Single ingredient object with full safety profile, synonyms, identifiers, and regulatory notes.
- Typical latency: sub-100ms median, <250ms p95.
- Cost: 1 credit per successful match. Unsuccessful matches (404) don't burn credits under credit-based pricing.
- Best for: Real-time scanner apps, ingredient detail pages, autocomplete dropdowns, "tap the ingredient to learn more" interactions.
- Batch Formulation Analyzer —
POST /v1/analyze- Request shape: JSON body with an
ingredientsarray (typically 10–500 strings) and an optionalregionparameter ("EU","US","CA","global"). - Response shape: Aggregate object (worst-case scores, allergen union, formulation warnings) plus a per-ingredient match array and an unmatched array.
- Typical latency: 100–500ms depending on array size — roughly linear above 50 ingredients.
- Cost: 1 credit per matched ingredient, not per request. A 50-ingredient batch with 48 matches consumes 48 credits.
- Best for: Product page enrichment at import time, formulation compliance scans, internal QA dashboards, bulk catalogue audits.
- Request shape: JSON body with an
- Pick single if the user is interacting one ingredient at a time, you need streaming UX (results appear as the user types), or you're building autocomplete. The round-trip overhead per request is acceptable because the user isn't waiting for fifty simultaneous results.
- Pick batch if you're enriching a product catalogue at write time (a brand uploads a new SKU), running nightly compliance audits, or rendering a full product safety summary in one page load. A 50-ingredient batch returns in roughly 200ms versus about 5 seconds of serial single requests — a 25× wall-clock improvement that users notice immediately.
- Hybrid pattern — use both. An e-commerce product page typically calls batch on initial render (one composite safety summary) and falls back to single lookups on tap or click for ingredient drill-down. This minimizes initial credit burn while keeping interactive UX snappy on the detail interactions that matter.
- Anti-pattern — don't fan out single requests in parallel from the client. Ten parallel single lookups still cost 10 credits and ten round-trips. The batch endpoint exists precisely so you don't do this. Fan-out also makes rate-limit handling and error reconciliation far messier than it needs to be.

A Working Example: Authenticating, Querying, and Handling Errors End to End
Every API contract reads cleanest when you trace one request through to its response and then through its failure modes. Below is a single lookup, a batch analyze, and the four error codes you should expect in production.
Authentication. The platform uses bearer tokens passed in the Authorization header. Tokens are issued per workspace via the dashboard. Never commit tokens to source control — load them from environment variables or a secret manager. Default rate limits are 1,000 requests per minute per workspace; contact sales for higher tiers if your catalogue enrichment job will saturate that ceiling during batch windows.
Single lookup — request:
GET /v1/ingredients/sodium%20lauryl%20sulfate HTTP/1.1
Host: api.dermalytics.dev
Authorization: Bearer YOUR_API_KEY
Accept: application/json
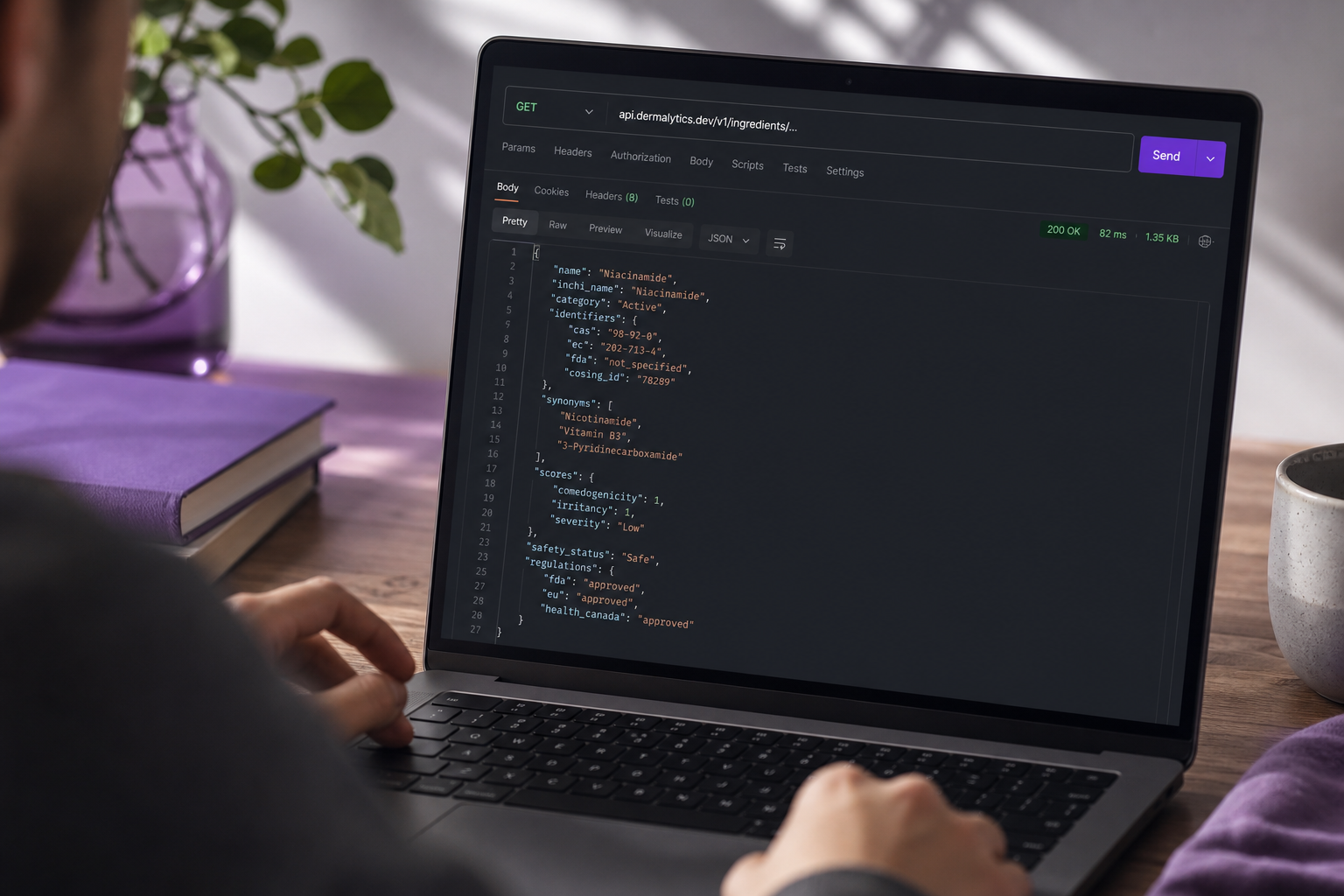
Single lookup — response:
// 200 OK
{
"inci_name": "Sodium Lauryl Sulfate",
"synonyms": ["SLS", "Sodium Dodecyl Sulfate"],
"identifiers": {
"cas": "151-21-3",
"ec": "205-788-1"
},
"safety_profile": {
"comedogenicity_score": 3,
"irritancy_score": 4,
"allergen_flags": ["irritant"],
"safety_status": "approved_eu_restricted_us"
},
"category": "Surfactant (Anionic)",
"regulatory_notes": [
"EU: Approved up to 60% in rinse-off, 2% leave-on (Annex VI)",
"US FDA: Listed as cosmetic ingredient",
"Canada: Permitted, not on Hotlist"
],
"source_last_updated": "2024-08-15"
}
Walk the response: safety_status is a compound jurisdictional string, not a boolean. regulatory_notes are human-readable strings derived from source annex references — render them in tooltips, not as standalone verdicts. And source_last_updated tells your caching layer when to refresh; key your TTL logic against it rather than wall-clock time.
Batch analyze — request:
POST /v1/analyze HTTP/1.1
Host: api.dermalytics.dev
Authorization: Bearer YOUR_API_KEY
Content-Type: application/json
{
"ingredients": [
"Water",
"Glycerin",
"Sodium Lauryl Sulfate",
"Phenoxyethanol",
"Mystery_Blend_X"
],
"region": "EU"
}
Batch analyze — response:
// 200 OK
{
"request_id": "batch_6f8k2j3k",
"ingredients_analyzed": 4,
"ingredients_unmatched": 1,
"aggregate_safety": {
"highest_irritancy_score": 4,
"highest_comedogenicity_score": 3,
"safety_status": "approved_eu",
"allergen_flags": ["irritant"],
"formulation_warnings": [
"Sodium Lauryl Sulfate at concentration >=1% in leave-on exceeds EU Annex VI limits"
]
},
"matched_ingredients": [ /* per-ingredient objects */ ],
"unmatched_ingredients": [
{ "raw_input": "Mystery_Blend_X", "reason": "no_match" }
]
}
The unmatched_ingredients array is the critical part of this payload. It tells your UI exactly what to surface as "we couldn't verify this ingredient." Don't silently drop unmatched inputs — display them with a "not verified" badge so users can see the gap rather than infer false coverage.
Error handling. Four codes account for nearly all production failures. Per the MDN HTTP status reference, implement each as a distinct branch in your client:
400 Bad Request— malformed body, invalidregionvalue, or non-string elements in theingredientsarray. Fix: validate client-side before sending. Schema-validate against the OpenAPI spec at build time and you'll catch most of these before they hit production traffic.401 Unauthorized— missing or invalid bearer token. Fix: verify the token, rotate if exposed, and confirm the workspace is active.404 Not Found— single lookup couldn't resolve the input. Important: this is not the same as "ingredient is unsafe." It means the input string didn't match. Render "Not in our reference database" rather than implying safety. This distinction matters for both UX and liability.429 Too Many Requests— rate limit exceeded. The response includes aRetry-Afterheader per RFC 6585. Implement exponential backoff per the Google Cloud retry guidance — start at 500ms, double up to 16s, jitter the intervals.5xxserver errors — rare under a 99.9% uptime SLA (roughly 8.76 hours of allowable downtime per year). Retry with backoff; surface stale cached data if available rather than blocking the user.
Always log the request_id from batch responses. When you contact support about a discrepancy, that ID lets the vendor trace the exact match path through their normalization layer in minutes rather than hours.
A 404 on an ingredient lookup is not a safety verdict. It means the string didn't resolve. Render that distinction in your UI or you'll teach users to trust silence as safety.
Official SDKs, Raw HTTP, or Generated Clients: Picking Your Integration Layer
You have three realistic options for talking to a cosmetic ingredient API: the vendor's official SDK, raw HTTP with your own client, or an SDK auto-generated from the OpenAPI 3 spec. Each has a clear best-fit scenario, and most production teams end up using more than one.
- Official SDKs (npm, PyPI). Dermalytics publishes
@dermalytics/sdkon npm anddermalyticson PyPI. You get typed methods, automatic retry with exponential backoff, bearer token management, and response caching with a default 24-hour TTL. Setup is roughly five minutes fromnpm installto first successful call. Best when shipping production code in Node, TypeScript, or Python — the saved engineering time on auth, retries, and error parsing typically runs 30–60 hours per language compared to rolling your own. The TTL-based cache alone can cut credit burn by roughly 40–60% in user sessions that re-query common ingredients like water and glycerin. - Raw HTTP (fetch, axios, requests, cURL). Direct calls against
https://api.dermalytics.dev/v1/...with manual bearer header construction. Best for quick prototyping, throwaway scripts, language environments without an official SDK (Go, Rust, Elixir, PHP), and one-off debugging from the terminal. The trade-off: you own retry logic, credential rotation, and cache invalidation. Plan for roughly 8–16 hours of integration scaffolding per language before you have something resembling production-grade behavior. - Generated SDKs from the OpenAPI 3 spec. The full contract is published at
api.dermalytics.devper the OpenAPI 3.0 specification. Tools like openapi-generator oroapi-codegenproduce typed clients in 50+ languages. Best when you need a typed client in a language without an official SDK and you're willing to maintain the generated code as the spec evolves. Generated clients lack the opinionated caching and retry policies of the official SDKs — you add those yourself or you live without them. - Hybrid in practice. Most production teams use the official SDK in application code and raw cURL or HTTPie in CI smoke tests and documentation examples. This keeps production fast and well-instrumented while preserving the ability to debug a wire-level response in ten seconds from a terminal. The pattern scales: as you add more services consuming the API (web client, mobile backend, internal admin tool), each adopts the SDK while ops scripts stay in raw HTTP.
Caching note. Whichever client you pick, cache aggressively at the ingredient level. INCI nomenclature doesn't change daily, and safety_status changes are tied to regulatory amendments that happen on quarterly-or-slower cadences. A 24-hour TTL on individual inci_name keys is conservative and safe; a 7-day TTL is reasonable for non-restricted ingredients. Key by the resolved inci_name, not the raw user input — that's where hit rates climb.
A 50KB SDK package is nothing compared to the forty hours you'd otherwise spend debugging credential rotation and exponential backoff. Install the SDK, cache aggressively, ship the feature.
Pre-Launch Audit: The Compliance, Monitoring, and Cost Control Checklist
Before your integration ships, walk a senior engineer or compliance reviewer through this checklist. Each item maps to a specific failure mode that has bitten production teams shipping ingredient data — from regional liability to runaway credit burn during an unanticipated import job.
- Jurisdiction enforcement is explicit. Your app reads the user's region (geo-IP, account setting, or storefront locale) before rendering safety verdicts. Never render an EU-only "approved" badge to a US user without qualification — the underlying regulatory frameworks aren't equivalent and the badge becomes misleading.
- INCI names render verbatim. You display the
inci_namefield exactly as returned — no truncation, no marketing renaming. Label-facing text must match the ICID Handbook standard, which the API mirrors. Any deviation from the canonical name undermines the cross-product comparison users expect. - Source attribution is visible. When you show severity scores, a tooltip or footnote credits the underlying regulatory sources (EU CosIng, FDA, Health Canada, CIR). This protects you from "where does this number come from?" challenges by retail partners or, eventually, regulators.
- Unmatched ingredients are surfaced, not hidden. The
unmatched_ingredientsarray drives a UI element that tells users "we couldn't verify these items" rather than implying everything was checked. Hiding unmatched inputs creates a false-coverage illusion that erodes trust the moment a user notices. - Cache invalidation respects
source_last_updated. Your cache keys include or check the source timestamp; you don't serve stale data past your TTL. A naive wall-clock TTL serves obsolete safety_status during regulatory amendments — exactly when freshness matters most. - Secrets are environment-loaded. API keys live in environment variables or a secret manager (AWS Secrets Manager, HashiCorp Vault, Doppler). No keys in client-side bundles, ever. Mobile builds in particular tend to leak secrets into shipped binaries; route every call through a server proxy.
- Rate limit handling is implemented. Your client respects
429 Retry-Afterper RFC 6585 and degrades gracefully — serving cached data or queuing the request rather than failing the user's interaction. Backoff without jitter creates thundering-herd problems; add randomization. - Allergen flags drive user-facing disclosure where required. EU Regulation 1223/2009 Annex III requires declaration of 24 fragrance allergens above threshold concentrations. If your app shows allergen flags, they tie to that list and not an arbitrary subset invented for the UI.
Operational monitoring. Wire these six metrics into your observability stack and set alerts on the red-flag thresholds.
| Metric | Target | Red flag | Why it matters |
|---|---|---|---|
| Requests per day | Track WoW | >10% spike WoW | Possible runaway loop |
| Credit burn per user | Per-cohort baseline | Trending up | Cache misconfigured |
| Unmatched rate | <5% of inputs | >10% | Indexing gap upstream |
| p95 latency | <300ms | >500ms | Oversized batches |
| 5xx error rate | <0.1% | >0.5% | Vendor or auth issue |
| Cache hit rate | >50% steady state | <30% | TTL or key mismatch |
Cost optimization patterns. A few moves cut credit burn substantially without changing product behavior:
- Batch over fan-out. Ten parallel single lookups cost the same in credits but roughly 5–10× more in latency and connection overhead. Use
/v1/analyzefor any payload greater than 3 ingredients. - Cache at the ingredient level, not the request level. Keying by
inci_name(after synonym resolution) gives far higher hit rates than keying by raw user input, since "SLS," "sls," and "Sodium Lauryl Sulfate" all collapse to one cache entry. - Pre-filter known noise. "Parfum/fragrance" is a proprietary placeholder, not a single ingredient — don't query it; handle the disclosure in UI. "Aqua/water" is so common a permanent client-side cache entry is appropriate and saves about 5–15% of typical credit volume.
- Set a monthly credit budget alert. Most credit-based APIs offer usage webhooks. Wire one to your ops channel at 70% and 90% of monthly budget so you're never surprised by a sprint-end overage.
Ship this checklist as a PR template the next time you wire an ingredient API into a new product surface. The audit isn't a one-time event before launch — it's the integration's running habit.