
How to Identify Niacinamide in Skincare Products: A Developer's Guide to Ingredient Parsing
You scraped an INCI string off a product page, wrote inciString.includes("niacinamide"), and shipped it. Your match rate is silently terrible — and you won't know why until someone files a bug. The molecule is right there in the bottle. It's just labeled "Nicotinamide" on one product, marketed as "Vitamin B3" on another, and sitting at position seven in a comma-mangled list with mixed casing and a trailing (4%) callout on a third. If you're building an ingredient scanner or adding transparency to a catalogue of skincare products with niacinamide, this is the bug you'll hit first.

Here is the technical reality. The same single chemical entity — niacinamide — appears under at least four names: niacinamide, nicotinamide, vitamin B3, and vitamin PP, all resolving to CAS 98-92-0 (EU CosIng). Meanwhile a near-identical-looking decoy, "niacin," is a completely different molecule (CAS 59-67-6) that a naive substring check will wrongly grab (SpecialChem). Three failure layers stack on top of each other: synonym divergence, unstructured text input, and false-positive substring traps. By the end of this guide you'll be able to detect, normalize, and enrich niacinamide reliably — by hand and via API — and the patterns generalize to any of the 25,000+ cosmetic ingredients you'll meet in the wild.
Table of Contents
- Why the Same Molecule Wears Four Different Names
- The Niacinamide Synonym Map: Every Name It Hides Behind
- Parsing a Raw INCI List by Hand: The Normalization Pipeline
- Doing It at Scale: Single Lookup vs. Batch Formulation Analysis
- Five Bugs That Quietly Corrupt Ingredient Matching
- Build Plan: Wiring Niacinamide Detection Into Your App
- Niacinamide Parsing: Developer FAQ
Why the Same Molecule Wears Four Different Names
Niacinamide and nicotinamide are chemically identical. Both are vitamin B3 derivatives sharing CAS 98-92-0 and the IUPAC name 3-pyridinecarboxamide (SpecialChem). Marketing copy frequently calls it "Vitamin B3" or the older "Vitamin PP" while the regulated INCI panel reads "NIACINAMIDE." Same molecule, four labels, depending entirely on who wrote the text and why.
That split between regulatory and marketing naming is the root of your matching problem. The INCI panel is the standardized, regulated ingredient name list printed on the back of the pack. Marketing names appear in product titles and front-of-pack claims — "Vitamin B3 Serum," "B3 Brightening Toner." A scanner that only reads marketing copy will miss the INCI panel's "NIACINAMIDE," and a scanner that only reads the INCI panel will never connect it to the "Vitamin B3" in the product title. Each surface exposes matches the other hides.
The fix is identifier anchoring, and it's the thesis of this entire guide: names are lossy; identifiers are not. CAS (98-92-0) and EC (202-713-4) numbers are the only unambiguous keys for this molecule. EU CosIng formally maps the INCI name "NIACINAMIDE" to CAS 98-92-0 and EC 202-713-4, with a documented cosmetic function of "smoothing" (EU CosIng). That mapping is your canonical join key. Every synonym you encounter should collapse to it.
A product name tells you what marketing wants you to see. The CAS number tells you what's actually in the bottle.
Scraped INCI lists are messy for reasons that compound. You'll meet inconsistent casing, Unicode variants (fullwidth characters, non-breaking spaces), ampersands standing in for "and," trailing parentheticals carrying concentration callouts, and localized spellings across markets. None of these change the molecule — all of them break a string comparison. Niacinamide ships as an odorless white crystalline powder registered for a wide variety of leave-on and rinse-off products (SpecialChem; UL Prospector). It appears in serums, moisturizers, cleansers, and toners alike — meaning your parser meets it in every product category and every label format you'll ever ingest.
There's a commercial reason to prioritize getting this one molecule right before any other. The niacinamide beauty products market was estimated at roughly USD 590.2 million in 2024, projected to reach about USD 846.5 million by 2030, according to Grand View Research (a vendor market report). A formulator's guide from Inspec Solutions (a vendor source) calls it "skincare's most versatile workhorse." Translated for the developer: this is a high-frequency ingredient that shows up across your entire catalogue of skincare products with niacinamide, and you cannot afford to miss it in your match logic. A 1% miss rate on a workhorse ingredient is a visible product defect.
This section explains why detection is hard. What it doesn't do is hand you the synonym set, the cleaning pipeline, or the API calls — those come next, in that order.
The Niacinamide Synonym Map: Every Name It Hides Behind
Here is the authoritative identity matrix. Five names collapse to one molecule; one decoy must never be allowed in.
| Name / Synonym | Type | Resolves to niacinamide? | CAS | EC |
|---|---|---|---|---|
| Niacinamide | INCI (regulatory) | Yes | 98-92-0 | 202-713-4 |
| Nicotinamide | Chemical / regulatory synonym | Yes | 98-92-0 | 202-713-4 |
| Vitamin B3 | Marketing / common name | Yes | 98-92-0 | 202-713-4 |
| Vitamin PP | Legacy / marketing | Yes | 98-92-0 | 202-713-4 |
| 3-Pyridinecarboxamide | IUPAC | Yes | 98-92-0 | 202-713-4 |
| Niacin (nicotinic acid) | DECOY — different molecule | No | 59-67-6 | — |
The first five rows all collapse to a single record keyed on CAS 98-92-0. That is the join key your data model should use — not the display string, not the INCI name, not the marketing label. Niacinamide, nicotinamide, vitamin B3, vitamin PP, and the IUPAC name 3-pyridinecarboxamide are five ways of writing the same chemical entity, and EU CosIng plus the SpecialChem dossier confirm they share the same CAS and EC identifiers (EU CosIng; SpecialChem). Store them as aliases of one record and the naming chaos disappears at the data layer.
The last row is where careless parsers ship false positives. "Niacin," also called nicotinic acid, is a distinct chemical entity with a different CAS (59-67-6) and different biological effects — it is not interchangeable with niacinamide and must never be treated as such (SpecialChem; PMC mechanistic review; Cosmetic Ingredient Review). The bug is mechanical and easy to write by accident: "niacinamide".includes("niacin") returns true. That single line is exactly why substring matching produces false positives — it grabs the decoy living inside the legitimate name. Exact-token matching is the fix, covered in the next section, and the full failure mode gets its own treatment in the bugs section further down.
Parsing a Raw INCI List by Hand: The Normalization Pipeline
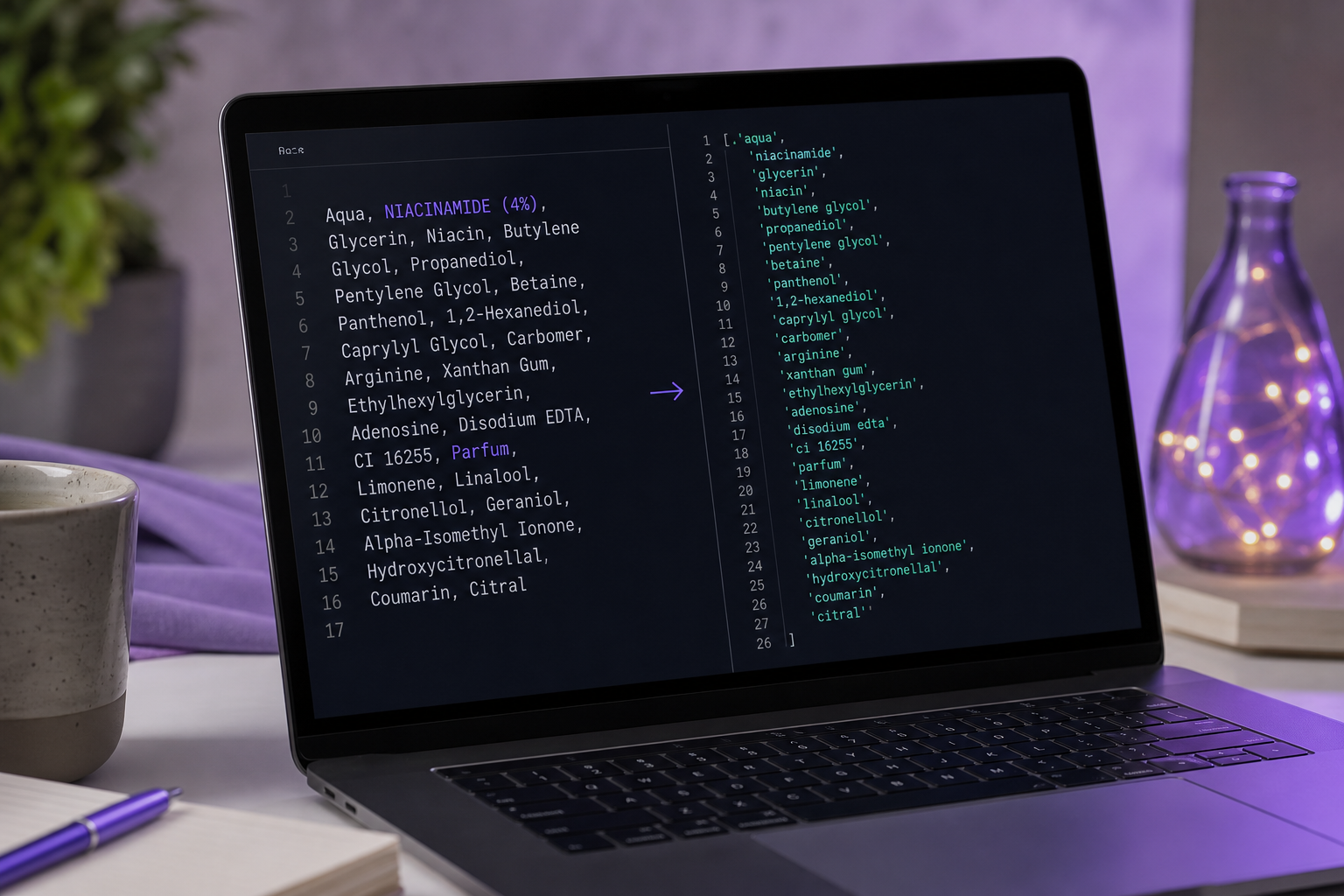
Before you match anything, you clean the string. Skip a step and you get either a silent miss or a false positive. Here's the sequence, with the failure mode each step prevents.

Step 1 — Lowercase + Unicode NFKC normalize. Fold the entire string to a single case and apply Unicode NFKC normalization. If you skip it: "Niacinamide," "NIACINAMIDE," and fullwidth or non-breaking-space variants compare as different strings and silently miss. NFKC collapses the visually-identical-but-byte-different characters that scraped HTML loves to inject.
Step 2 — Strip parentheticals and concentration markers. Remove trailing callouts like (4%) or (niacinamide 5%). If you skip it: the token becomes niacinamide (4%) and never equals your map key. INCI does not standardize percentage disclosure, so these callouts are inconsistent noise rather than reliable data — more on why in the FAQ.
Step 3 — Split on commas and bullet separators, trim whitespace. Tokenize on ,, •, and ;, then trim each token. If you skip it: you match against the whole blob instead of individual ingredients, which destroys the positional information INCI ordering carries.
Step 4 — Token-match against the synonym set, EXACT not substring. Compare each cleaned token against the full synonym set from the identity matrix using equality, not containment. If you skip it: substring matching grabs "niacin" inside "niacinamide" — and vice versa — producing the canonical false positive.
Step 5 — Resolve to CAS as the canonical key. Once a token matches any synonym, store CAS 98-92-0 as the record's primary key, not the display string (EU CosIng). If you skip it: your catalogue fragments across languages and naming variants with no stable join, and dedup quietly fails.
This pipeline is entirely viable for one ingredient. You write five small functions, a unit test, and a synonym constant, and niacinamide detection works. It breaks down the moment you try to repeat it across thousands of ingredients — each with its own synonym set, its own decoys, and its own regulatory revisions. That's the problem the next section solves.
Doing It at Scale: Single Lookup vs. Batch Formulation Analysis
Hand-rolling a synonym map for one molecule is an afternoon. Hand-rolling it for the full ingredient universe is a standing maintenance commitment you'll regret. Regulatory data drifts, the ingredient universe spans 25,000+ entries, and the burden compounds with every market you launch in. Normalizing data across FDA, EU CosIng, and Health Canada by hand is not a one-time job — it's a subscription you pay in engineering time forever.
When you do reach for an API, the choice is between two endpoints. Here's how they split.
| Criterion | GET /v1/ingredients/{name} | POST /v1/analyze |
|---|---|---|
| Input size | Single ingredient | Full INCI / formulation |
| Best for | Enriching one known ingredient | Scanning a whole product label |
| Returns overall safety_status | No (single record) | Yes (aggregated) |
| Latency profile | Sub-100ms median | Sub-100ms median |
| Credit cost basis | Per successful match | Per successful match |
| Typical caller | Detail page / tooltip lookup | Scanner / bulk catalogue ingest |
Look at the response shape and the division of labor becomes obvious. A single-ingredient lookup returns a severity label, a comedogenicity score (0–5), an irritancy score (0–5), CAS and EC identifiers, a synonyms array — which is precisely the niacinamide synonym set you'd otherwise maintain by hand — and a safety_status. The batch endpoint takes a full INCI string and aggregates the per-ingredient data into one formulation-level safety_status, so you don't write the roll-up logic yourself. If your UI shows individual ingredient detail pages, the single lookup fits. If you're scanning whole labels and need a verdict on the formulation, the batch analyzer fits.
![A developer monitor showing a formatted JSON API response, with the niacinamide record block highlighted — visible fields: "cas":"98-92-0", "synonyms":["nicotinamide","vitamin B3"], "comedogenici](https://washtub.s3.eu-central-1.amazonaws.com/cmqpcz9qn000004jlbz1se1aw/photo-3.png)
The structured scores matter more than they look. Niacinamide is generally well-tolerated and barrier-supportive, but dermatologists are explicit that mild irritation or redness is possible, particularly at higher concentrations or on compromised skin (Alamo Heights Dermatology; Mid County Dermatology). A hardcoded "safe/unsafe" boolean cannot express "well-tolerated but occasionally irritating at high concentration." A 0–5 irritancy score can. That nuance is the difference between a scanner users trust and one they catch being wrong.
Maintaining your own synonym table is free until the regulatory data shifts under you — then it's the most expensive line of code you own.
Official SDKs ship on npm and PyPI, and the credit model charges only on a successful match. Because you pay per match returned, a cache-then-call pattern directly controls spend: resolve once, store the CAS record, and short-circuit every repeat lookup. That's the first item on the build checklist below.
Five Bugs That Quietly Corrupt Ingredient Matching
Each of these ships clean, passes a happy-path test, and corrupts your data in production. Symptom, consequence, fix.
The substring trap. Symptom: token.includes("niacin") matches "niacinamide." Consequence: you tag products containing niacin — nicotinic acid, CAS 59-67-6 — as niacinamide, CAS 98-92-0, conflating two different molecules with different effects (SpecialChem). Fix: exact token matching against the synonym set, never substring containment.
The casing / Unicode miss. Symptom: "Niacinamide" ≠ "niacinamide" ≠ a fullwidth variant under naive comparison. Consequence: false negatives that look exactly like the ingredient being absent, so nobody investigates. Fix: lowercase plus NFKC normalize before any comparison — step one of the pipeline above.
The name-only key. Symptom: you store the display string as your primary key. Consequence: the same molecule fragments into separate records across languages and naming conventions, breaking deduplication and any cross-catalogue join. Fix: key on CAS 98-92-0 (EU CosIng).
The silent empty match. Symptom: zero results returned, treated as "ingredient not present." Consequence: a parse failure or an unknown synonym becomes indistinguishable from genuine absence, and you under-report coverage without knowing it. Fix: distinguish "no match returned" from "confirmed absent," and log every unmatched token for review.
The stale synonym set. Symptom: a hardcoded name list that never updates. Consequence: it rots as registries — FDA, EU CosIng, Health Canada — revise entries, and both ingredient data and market estimates drift over time (Grand View Research). Fix: source synonyms from a maintained synonyms array rather than a static constant frozen at deploy time.
Build Plan: Wiring Niacinamide Detection Into Your App
Execute these in order. By the end you have detection that survives real-world labels.
- Choose CAS as your canonical key. Set CAS 98-92-0 as the primary identifier in your data model so niacinamide, nicotinamide, vitamin B3, and vitamin PP all collapse to one record (EU CosIng). Every downstream join depends on this decision, so make it first.
- Normalize every incoming INCI string. Reuse the pipeline above: NFKC plus lowercase, strip parentheticals and concentration markers, tokenize on commas and bullets, trim each token. No string reaches your matcher uncleaned.
- Pick your endpoint per use case. Single-ingredient enrichment for a detail page or tooltip goes to
GET /v1/ingredients/{name}. Full-label scanning that needs an aggregatedsafety_statusgoes toPOST /v1/analyze. Match the endpoint to the surface, per the decision matrix. - Install the SDK and pull the contract. Add the official npm or PyPI package and pull the OpenAPI 3 spec from api.dermalytics.dev to generate typed clients, so your request and response shapes stay in sync with the API.
- Cache successful matches. Because credits are charged only on successful matches, cache resolved CAS records and short-circuit repeat lookups. The same product scanned a thousand times should cost one match, not a thousand.
- Surface the structured scores in your UI. Display the severity label, comedogenicity (0–5), and irritancy (0–5) rather than a binary flag. Niacinamide is generally well-tolerated but can mildly irritate some users, so let the score communicate that nuance instead of flattening it to a single yes/no (Alamo Heights Dermatology).
- Add a synonym and decoy test suite. Assert that "nicotinamide" and "vitamin B3" resolve to CAS 98-92-0, and — most importantly — that "niacin" and "nicotinic acid" do not, resolving instead to CAS 59-67-6 (SpecialChem). This regression-guards the substring trap so it can never silently return.
With this in place, your app reliably identifies skincare products with niacinamide regardless of how the label spells it — and the same seven steps generalize to every other ingredient in your catalogue.
Niacinamide Parsing: Developer FAQ
Is niacinamide the same as niacin?
No. Niacinamide (CAS 98-92-0) and niacin, also called nicotinic acid (CAS 59-67-6), are distinct molecules with different biological effects, even though their names share a prefix. Matching "niacin" to "niacinamide" via substring is the single most common ingredient-parsing bug there is — always match exact tokens and key on CAS, never on the display name (SpecialChem; PMC).
Can I detect niacinamide concentration from an INCI list?
Generally no. INCI convention orders ingredients by descending concentration above 1%, so position is a coarse signal — an ingredient near the top is present in greater quantity than one near the bottom. But lists do not state percentages. Some labels carry a parenthetical callout like "(4%)," yet it's inconsistent across brands and unreliable as structured data. The Cosmetic Ingredient Review compiles use-concentration ranges across product categories at the regulatory level, not per individual label (Cosmetic Ingredient Review). An ingredient API returns structured identity, synonyms, and safety scores — not a parsed concentration percentage you can trust.
Which regulatory source is the canonical record?
Rather than picking one registry and betting on it, use a source that normalizes FDA, EU CosIng, and Health Canada into a single programmatic record keyed on CAS and EC. EU CosIng, for instance, maps the INCI name "NIACINAMIDE" to CAS 98-92-0 and EC 202-713-4 (EU CosIng). Anchoring on the CAS and EC identifiers — not any single registry's display name — keeps your record stable as individual registries revise their entries over time.